金币
UID1628
帖子
主题
积分1187
注册时间2011-8-15
最后登录1970-1-1
听众
性别保密
|
欢迎您注册蒲公英
您需要 登录 才可以下载或查看,没有帐号?立即注册
x
本帖最后由 calvin 于 2018-3-17 20:52 编辑
简介
本次从猎聘网上获取了4400条招聘信息,信息内容包括:岗位,工作年限要求,薪资。然后对该数据进行清洗,删除研发、销售、IT、行政等岗位。仅保留质量部、工程部、生产部、统计分析、注册、仓库的数据。以为已在药厂从事相关工作的朋友提供一个参考。如需所有原始数据,请自行用附件A的R代码爬取。本报告仅分析岗位需求。
注:本次数据获取仅自行研究和有限范围的展示,其它人请勿用做它用以及一些有可能损害相关利益方利益的行为。
数据清洗
- library(stringr)
- library(ggplot2)
- td<-read.csv("drugpositionclean.csv",stringsAsFactors = FALSE)
- td$group<-td$position
- td$group[str_detect(td$position,pattern="\\w*QA\\w*")]<-"QA"
- td$group[str_detect(td$position,pattern="\\w*QC\\w*")]<-"QC"
- td$group[str_detect(td$position,pattern="\\w*质量\\w*")]<-"Quality"
- td$level[str_detect(td$position,pattern="\\w*主管\\w*")]<-"主管"
- td$level[str_detect(td$position,pattern="\\w*经理\\w*")]<-"经理"
- td$level[str_detect(td$position,pattern="\\w*主任\\w*")]<-"主任"
- td$level[str_detect(td$position,pattern="\\w*总监\\w*")]<-"总监"
- td$level[is.na(td$level)]<-"None"
岗位分布
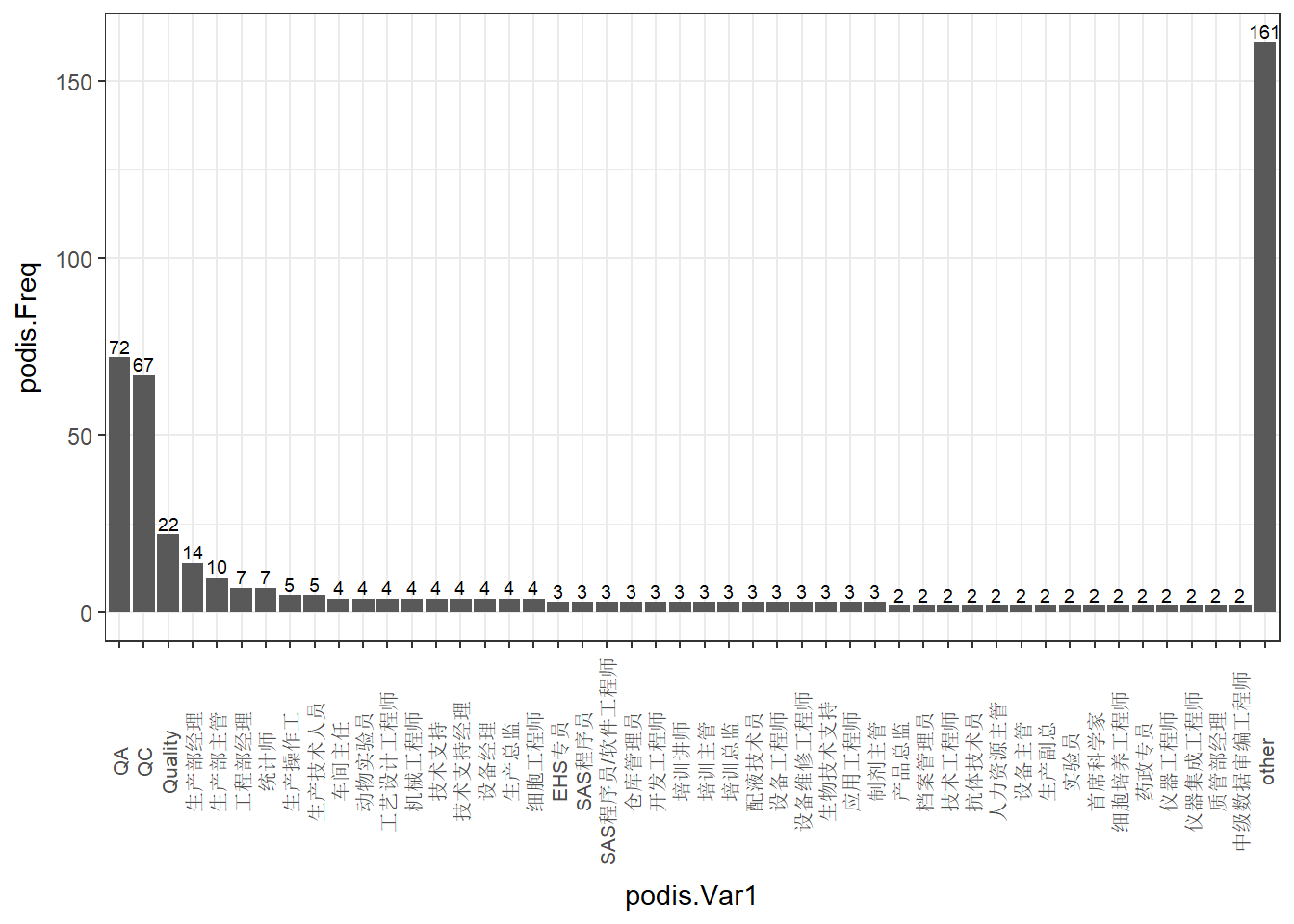
对频次只有1的进行合并,合并为“其它”,画折线图,我们可以看出质量相关人员需求还是蛮大的。td$group[td$group %in% names(table(td$group))[table(td$group)==1]]<-"other"
- podis<-sort(table(td$group),decreasing = T)
- podis<-data.frame(podis=podis[c(2:length(podis),1)])
- ggplot(podis,aes(x=podis.Var1,y=podis.Freq))+geom_bar(stat="identity")+theme_bw()+theme(axis.text.x=element_text(angle=90,vjust=0.5,size=rel(0.9)))+geom_text(aes(label=podis.Freq),vjust=-0.3,size=2.5)
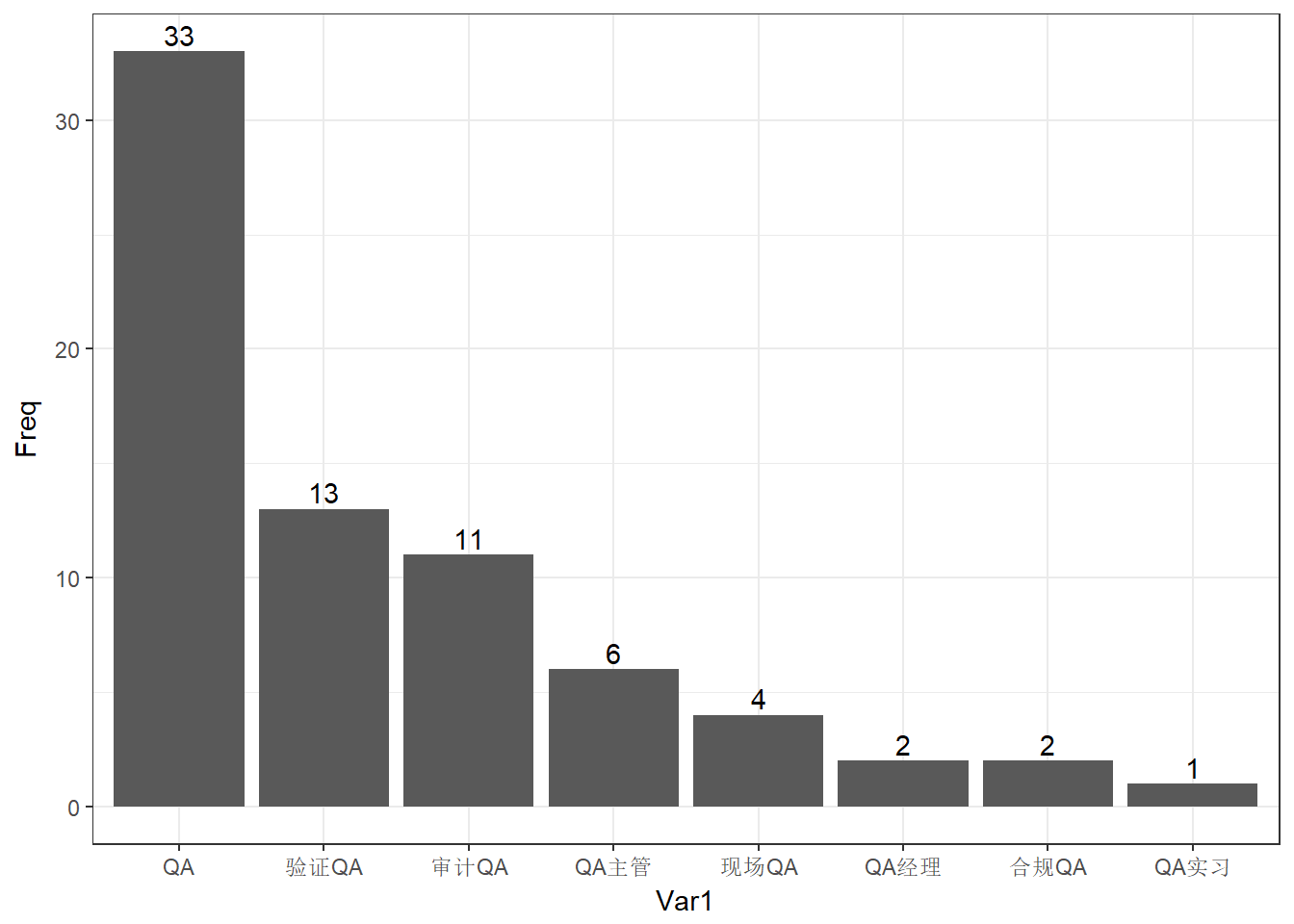
对于质量部QA相关人员,我们再进行详细的挖掘。QAdetail<-td$position[str_detect(td$position,pattern="\\w*QA\\w*")]
- QAdetail<-sort(table(str_sub(QAdetail,start=1,end=4)),decreasing = T)
- ggplot(data.frame(QAdetail),aes(x=Var1,y=Freq))+geom_bar(stat="identity")+theme_bw()+geom_text(aes(label=Freq),vjust=-0.3)
附件A
爬虫代码
- {r,echo=TRUE,eval=FALSE}
- library(Rwebdriver)
- library(XML)
- library(stringr)
- # Run the server
- start_session(root="http://localhost:4444/wd/hub/",browser="chrome")
- # Get the subject list.
- post.url("https://www.liepin.com/zhaopin/?industryType=industry_10&fromSearchBtn=2&ckid=80b9029c43a8be95&industries=270&init=-1&flushckid=1&headckid=80b9029c43a8be95&d_pageSize=40&siTag=1B2M2Y8AsgTpgAmY7PhCfg%7EfA9rXquZc5IkJpXC-Ycixw&d_headId=db463eab01d5e0a26aca705a4e4b76ae&d_ckId=db463eab01d5e0a26aca705a4e4b76ae&d_sfrom=search_fp_nvbar&d_curPage=0")
- pagesource<-page_source()
- Encoding(pagesource)<-"UTF-8"
- pagesource
- pagesource <- htmlParse(pagesource,encoding = "UTF-8")
- xpathSApply(pagesource,"//div[@class='job-info']//a",xmlValue)
- url_list<-str_extract_all(pagesource,"coser/detail/\\d*/\\d*")
- url_list<-str_c("https://bcy.net/coser/detail",unlist(str_extract_all(unlist(url_list),"/\\d*/\\d*")))
- # Create the handle
- handle<-getCurlHandle(useragent=str_c(R.version$platform,R.version$version.string,sep=", "),httpheader=c(from="111@qq.com"))
- # Define download function
- downloadPIC<-function(url_list){
- dir.create(paste0("E:\\image\",Sys.Date()))
- for(i in 1:length(url_list)){
- post.url(url=url_list[i])
- pagesource_pic<-page_source()
- Encoding(pagesource_pic)<-"utf-8"
- pic_list<-unlist(str_extract_all(pagesource_pic,"https:.*?\\.jpg"))
- for(j in 1:length(pic_list)){
- writeBin(getBinaryURL(pic_list[j]),paste0("E:\\image\",Sys.Date(),"\",i,"-",j,".jpg"))
- }
- }
- }
更多内容请关注微信公众号:DataSciences

|
|

 |手机版|蒲公英|ouryao|蒲公英
( 京ICP备14042168号-1 ) 增值电信业务经营许可证编号:京B2-20243455 互联网药品信息服务资格证书编号:(京)-非经营性-2024-0033
|手机版|蒲公英|ouryao|蒲公英
( 京ICP备14042168号-1 ) 增值电信业务经营许可证编号:京B2-20243455 互联网药品信息服务资格证书编号:(京)-非经营性-2024-0033





 发表于 2018-3-17 20:52:12
发表于 2018-3-17 20:52:12

 置顶卡
置顶卡 变色卡
变色卡